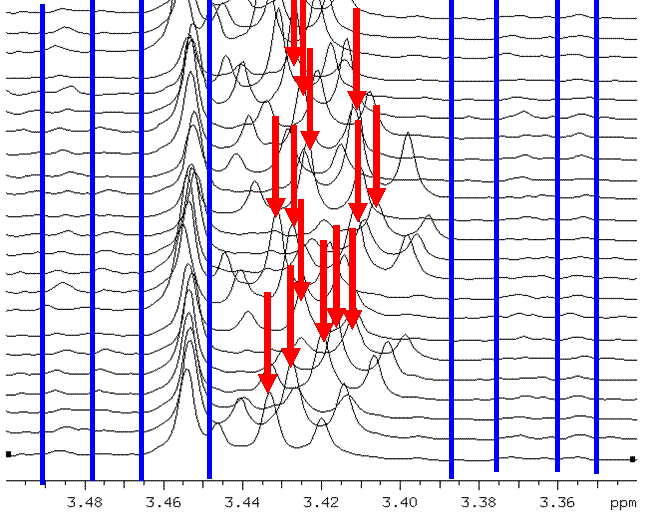
To prevent peaks being cut by the boundaries of bins, which is an often-observed effect in the case of equidistant binning, methods have been proposed, which are based on non-equidistant spacing of bins. In the ideal case, the borders of the bins are adjusted in a way that bins cover only complete peaks including all possible locations of the peaks. This means that the bin width depends on the width of the peak shape and on the shift width of the peak. An example is shown in the figure. None of the peaks is cut by the bin boundaries. The width of the bin covering the peak of para-hydroxyphenylacetate (locate at 3.455 ppm) is narrow, as the peak does not shift. On the other side, the triplet of taurine is quite wide and shows extensive shifts. Therefore, the corresponding bin is very wide (from 3.386 ppm to 3,448 ppm).
The binning shown in the figure is based on positioning the borders of the bins on local minima of the mean spectrum of the complete sample set of 690 spectra. The considerable number of spectra results in a very smooth spectrum. Therefore, the local minima separate well between shifting peaks while conserving each peak in a bin. For static peaks, the hyperfine structure is split into separate bins. Overall, 604 bins were generated in this case for the spectral range of 0 ppm to 10 ppm with the water peak excluded.
Non-equidistant binning applied to a set of 1H-NMR spectra of 30 samples from a human metabonomic study. The bin borders are marked by blue lines . It is visible, that the taurine peak (triplets marked with a red arrows) does not shift between bins but is located within a wide bin.
The unequal bin width also has some fundamental consequences for the subsequent data analysis. For the example discussed above, the bin width varied between 0.0014 ppm and 0.46 ppm (broad peak of urea). If no further processing of the spectrum is performed, data points belonging to different bins influence the subsequent data analysis to a different extent. For example, a data point of a very small bin has a higher influence than a data point of a very wide bin. If the subsequent data analysis should represent the data points of the raw spectra as adequate as possible, it might be appropriate to scale the integral of the bins by the inverse of the bin width. On the other side, each bin represents one single signal in the ideal case. Therefore the integral of a bin represents the “proton concentration” and with it the concentration of the metabolite behind the signal. Thus, no further scaling is needed, if the data analysis should reveal concentrations of metabolites and changes of concentrations of metabolites.
A combination of equidistant binning and non-equidistant binning has been proposed and applied in metabonomics studies recently[1] ,[2],[3] . This method starts with the traditional bucket size of 0.04 ppm and allows adjusting the borders by 50% resulting in a bucket width between 0.02 ppm and 0.06 ppm. The adjustment is based on finding local minima of a sum of spectra or of a skyline projection of spectra.
[2] B. Lefebvre, R. Sasaki , S. Golotvin and A. Nicholls, Intelligent Bucketing for Metabonomics – Part 2, Poster, http://www.acdlabs.com/download/publ/2004/intelbucket2.pdf
[3] L. Schnackenberg, R.D. Beger and Y. Dragan, Metabolomics, 1 (2005) 87